为 Python 设计的状态机库 Transitions 开发文档 (中文翻译)
Transitions 是一个轻量级的、面向对象的 Python 状态机实现,包含许多扩展功能。兼容 Python 2.7+ 和 3.0+。
安装
pip install transitions
快速入门
俗话说,一个好的例子抵得上 100 页 API 文档、一百万个指令或一千句话。
好吧,说这话的人可能有点夸张... 但不管怎样,这里有一个例子:
from transitions import Machine
import random
class 嗜睡超级英雄(object):
# 定义一些状态。大多数时候,嗜睡超级英雄就像普通人一样。
# 除了...
states = ['睡觉中', '闲逛中', '饥饿中', '满身汗', '拯救世界']
def __init__(self, name):
# 在我的地盘上不允许有无名的超级英雄!每个嗜睡超级英雄都必须有名字。
# 任何名字都行。瞌睡侠、梦游女。你懂的。
self.name = name
# 今天我们救了啥?
self.kittens_rescued = 0
# 初始化状态机
self.machine = Machine(model=self, states=嗜睡超级英雄.states, initial='睡觉中')
# 添加一些转换。我们也可以像上面定义状态那样,用一个字典的静态列表来定义它们,
# 然后将这个列表作为 transitions= 参数传给 Machine 的初始化器。
# 某个时刻,每个超级英雄都必须起床亮相。
self.machine.add_transition(trigger='唤醒', source='睡觉中', dest='闲逛中')
# 超级英雄需要保持身材。
self.machine.add_transition('锻炼', '闲逛中', '饥饿中')
# 消耗的卡路里不会自己补充!
self.machine.add_transition('吃', '饥饿中', '闲逛中')
# 超级英雄随时待命。永远待命。但他们并不总是穿着适合工作的服装。
self.machine.add_transition('求救信号', '*', '拯救世界',
before='换上超级秘密战衣')
# 他们下班时,浑身是汗,脏兮兮的。但在做其他事情之前,
# 他们必须仔细记录他们最新的冒险经历。因为法律部门这么说。
self.machine.add_transition('完成任务', '拯救世界', '满身汗',
after='更新日志')
# 汗水是一种可以通过水解决的状况。
# 除非你度过了特别漫长的一天,那样的话... 就该睡觉了!
self.machine.add_transition('清洁', '满身汗', '睡觉中', conditions=['筋疲力尽了吗'])
self.machine.add_transition('清洁', '满身汗', '闲逛中')
# 我们的嗜睡超级英雄几乎可以在任何时间睡着。
self.machine.add_transition('小睡', '*', '睡觉中')
def 更新日志(self):
""" 亲爱的日记,今天我救了胡须先生。又一次。 """
self.kittens_rescued += 1
@property
def 筋疲力尽了吗(self):
""" 基本上就是抛硬币。 """
return random.random() < 0.5
def 换上超级秘密战衣(self):
print("帅吧?")
好了,现在你已经把一个状态机烘焙进了 嗜睡超级英雄。让我们带他/她/它出去遛遛...
>>> 蝙蝠侠 = 嗜睡超级英雄("蝙蝠侠")
>>> 蝙蝠侠.state
'睡觉中'
>>> 蝙蝠侠.唤醒()
>>> 蝙蝠侠.state
'闲逛中'
>>> 蝙蝠侠.小睡()
>>> 蝙蝠侠.state
'睡觉中'
>>> 蝙蝠侠.清洁()
MachineError: "无法从状态 '睡觉中' 触发事件 '清洁'!"
>>> 蝙蝠侠.唤醒()
>>> 蝙蝠侠.锻炼()
>>> 蝙蝠侠.state
'饥饿中'
# 蝙蝠侠还没干任何有用的事...
>>> 蝙蝠侠.kittens_rescued
0
# 我们现在为您直播一场可怕的小猫被困事件现场...
>>> 蝙蝠侠.求救信号()
'帅吧?'
>>> 蝙蝠侠.state
'拯救世界'
# 回基地。
>>> 蝙蝠侠.完成任务()
>>> 蝙蝠侠.state
'满身汗'
>>> 蝙蝠侠.清洁()
>>> 蝙蝠侠.state
'睡觉中' # 太累了,澡都不洗了!
# 又是高效的一天,阿尔弗雷德。
>>> 蝙蝠侠.kittens_rescued
1
虽然我们无法读懂真正蝙蝠侠的心思,但我们肯定可以可视化我们的 嗜睡超级英雄 的当前状态。
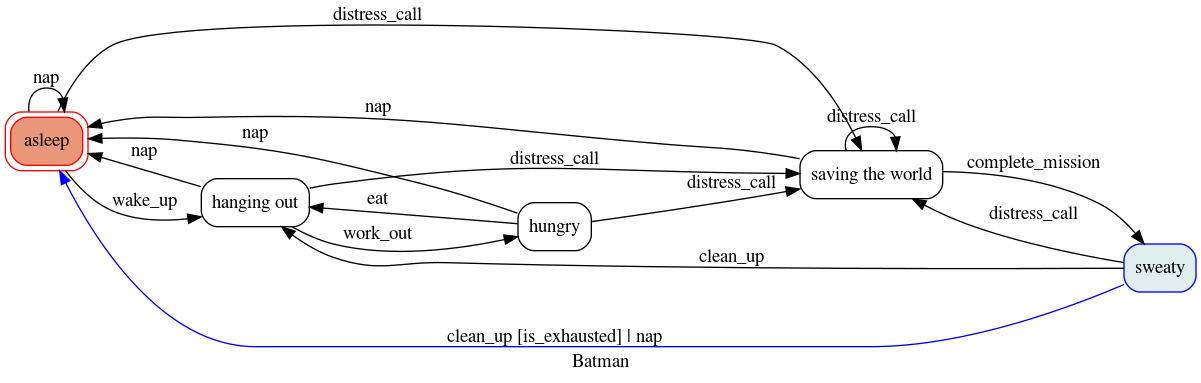
如果你想了解如何做到,可以看看 图表 扩展。
非快速入门
状态机是行为的一个模型,由有限数量的状态和这些状态之间的转换组成。在每个状态和转换中,都可以执行一些动作。状态机需要从某个初始状态开始。使用 transitions 时,状态机可能由多个对象组成,其中一些(机器)包含用于操作其他(模型)对象的定义。下面,我们将看一些核心概念以及如何使用它们。
一些关键概念
- 状态。状态表示状态机中一个特定的条件或阶段。它是一个行为的不同模式或过程中的一个阶段。
- 转换。这是导致状态机从一个状态改变到另一个状态的过程或事件。
- 模型。实际的有状态结构。它是在转换过程中被更新的实体。它还可以定义在转换期间执行的动作。例如,就在转换之前,或当进入或退出一个状态时。
- 机器。这是管理并控制模型、状态、转换和动作的实体。它是协调状态机整个过程的指挥者。
- 触发器。这是启动转换的事件,即发送信号开始转换的方法。
- 动作。在进入某个状态、退出某个状态或转换期间执行的特定操作或任务。动作通过回调实现,回调是在某些事件发生时执行的函数。
基本初始化
启动并运行一个状态机相当简单。假设你有一个对象 lump(Matter 类的一个实例),并且你想管理它的状态:
class 物质(object):
pass
lump = 物质()
你可以像这样初始化一个绑定到模型 lump 的(最小化)工作状态机:
from transitions import Machine
machine = Machine(model=lump, states=['固态', '液态', '气态', '等离子态'], initial='固态')
# Lump 现在有了一个新的 state 属性!
lump.state
>>> '固态'
另一种方法是不显式地将模型传递给 Machine 初始化器:
machine = Machine(states=['固态', '液态', '气态', '等离子态'], initial='固态')
# 此时 machine 实例本身充当模型
machine.state
>>> '固态'
请注意,这次我没有将 lump 模型作为参数传递。传递给 Machine 的第一个参数充当模型。所以当我在那里传递了某些东西时,所有便捷函数都将添加到该对象上。如果没有提供模型,则 machine 实例本身充当模型。
一开始我说“最小化”,是因为虽然这个状态机在技术上可以运行,但它实际上什么也不做。它从 '固态' 状态开始,但永远不会移动到另一个状态,因为还没有定义任何转换... 目前!
让我们再试一次。
# 状态
states=['固态', '液态', '气态', '等离子态']
# 以及状态之间的一些转换。我们很懒,所以会省略
# 逆相变(凝固、凝结等)。
transitions = [
{ 'trigger': '融化', 'source': '固态', 'dest': '液态' },
{ 'trigger': '蒸发', 'source': '液态', 'dest': '气态' },
{ 'trigger': '升华', 'source': '固态', 'dest': '气态' },
{ 'trigger': '电离', 'source': '气态', 'dest': '等离子态' }
]
# 初始化
machine = Machine(lump, states=states, transitions=transitions, initial='液态')
# 现在 lump 维护状态...
lump.state
>>> '液态'
# 并且状态可以改变...
# 可以调用闪亮的新触发器方法
lump.蒸发()
lump.state
>>> '气态'
# 或者直接调用 trigger 方法
lump.trigger('电离')
lump.state
>>> '等离子态'
注意那些附加到 物质 实例的闪亮的新方法(蒸发()、电离() 等)。
每个方法触发相应的转换。
转换也可以通过调用提供的 trigger() 方法并传入转换名称来动态触发,如上所示。
更多内容见 触发转换 部分。
状态
任何好的状态机(以及许多不好的状态机,毫无疑问)的灵魂都是一组状态。上面,我们通过传递一个字符串列表给 Machine 初始化器来定义有效的模型状态。但在内部,状态实际上表示为 State 对象。
你可以通过多种方式初始化和修改 State。具体来说,你可以:
- 传递一个字符串给
Machine初始化器,给出状态的名称,或者 - 直接初始化每个新的
State对象,或者 - 传递一个带有初始化参数的字典
以下代码片段说明了实现相同目标的几种方法:
# 导入 Machine 和 State 类
from transitions import Machine, State
# 创建包含 3 个状态的列表,传递给 Machine 初始化器。
# 我们可以混合类型;在这个例子中,
# 我们传递一个 State,一个字符串,和一个 dict。
states = [
State(name='固态'),
'液态',
{ 'name': '气态'}
]
machine = Machine(lump, states)
# 这个替代例子展示了更显式的
# 状态和状态回调的添加方式,但最终
# 结果与上面相同。
machine = Machine(lump)
solid = State('固态')
liquid = State('液态')
gas = State('气态')
machine.add_states([solid, liquid, gas])
状态在添加到机器时被初始化一次,并将持续存在直到从机器中移除。换句话说:如果你更改状态对象的属性,这种更改在下次进入该状态时将不会重置。如果你需要其他行为,请查看如何 扩展状态特性。
回调
但仅仅有状态并且能够在它们之间移动(转换)本身并不是很有用。如果你想在进入或退出一个状态时做点事情,执行一些动作呢?这就是回调的用武之地。
一个 State 还可以与 enter 和 exit 回调列表相关联,每当状态机进入或离开该状态时,这些回调就会被调用。你可以在初始化期间通过将它们传递给 State 对象构造函数、在状态属性字典中传递它们来指定回调,或者稍后添加它们。
为方便起见,每当一个新的 State 被添加到 Machine 时,方法 on_enter_«state name» 和 on_exit_«state name» 会在 Machine 上(而不是模型上!)动态创建,允许你稍后根据需要动态添加新的进入和退出回调。
# 我们旧的物质类,现在有了几个新方法,
# 我们可以在进入或退出状态时触发它们。
class 物质(object):
def 问好(self): print("你好,新状态!")
def 道别(self): print("再见,旧状态!")
lump = 物质()
# 状态与上面相同,但现在我们给 StateA 一个退出回调
states = [
State(name='固态', on_exit=['道别']),
'液态',
{ 'name': '气态', 'on_exit': ['道别']}
]
machine = Machine(lump, states=states)
machine.add_transition('升华', '固态', '气态')
# 回调也可以在初始化后使用动态添加的
# on_enter_ 和 on_exit_ 方法添加。
# 注意,添加回调的初始调用是在 Machine 上进行的,
# 而不是在模型上。
machine.on_enter_气态('问好')
# 测试回调...
machine.set_state('固态')
lump.升华()
>>> '再见,旧状态!'
>>> '你好,新状态!'
请注意,当 Machine 首次初始化时,on_enter_«state name» 回调将不会触发。例如,如果你定义了一个 on_enter_A() 回调,并且用 initial='A' 初始化 Machine,那么 on_enter_A() 在下次进入状态 A 之前不会触发。(如果你需要确保 on_enter_A() 在初始化时触发,你可以简单地创建一个虚拟的初始状态,然后在 __init__ 方法中显式调用 to_A()。)
除了在初始化 State 时传入回调或动态添加它们外,还可以在模型类本身中定义回调,这可能会提高代码清晰度。例如:
class 物质(object):
def 问好(self): print("你好,新状态!")
def 道别(self): print("再见,旧状态!")
def on_enter_A(self): print("我们刚进入了状态 A!")
lump = 物质()
machine = Machine(lump, states=['A', 'B', 'C'])
现在,任何时候 lump 转换到状态 A,在 物质 类中定义的 on_enter_A() 方法就会触发。
你可以使用 on_final 回调,当进入一个 final=True 的状态时,它们将被触发。
from transitions import Machine, State
states = [State(name='待命中'),
State(name='救援小猫中'),
State(name='坏人已逃', final=True),
State(name='坏人被捕', final=True)]
transitions = [["接到呼叫", "待命中", "救援小猫中"], # 一叫我们就来
{"trigger": "干预",
"source": "救援小猫中",
"dest": "坏人已逃", # 我们
"conditions": "坏人更快"}, # 除非他们更快
["干预", "救援小猫中", "坏人被捕"]]
class 最终版超级英雄(object):
def __init__(self, speed):
self.machine = Machine(self, states=states, transitions=transitions, initial="待命中", on_final="宣告成功")
self.speed = speed
def 坏人更快(self, offender_speed):
return self.speed < offender_speed
def 宣告成功(self, **kwargs):
print("小猫安全了。")
hero = 最终版超级英雄(speed=10) # 我们今天状态不好
hero.接到呼叫()
assert hero.is_救援小猫中()
hero.干预(offender_speed=15)
# >>> '小猫安全了'
assert hero.machine.get_state(hero.state).final # 结束了
assert hero.is_坏人已逃() # 也许下次...
检查状态
你可以随时通过以下任一方式检查模型的当前状态:
- 检查
.state属性,或者 - 调用
is_«state name»()
如果你想要获取当前状态的实际 State 对象,可以通过 Machine 实例的 get_state() 方法来完成。
lump.state
>>> '固态'
lump.is_气态()
>>> False
lump.is_固态()
>>> True
machine.get_state(lump.state).name
>>> '固态'
如果你愿意,可以在初始化 Machine 时通过传递 model_attribute 参数来选择自己的状态属性名称。这也会将 is_«state name»() 的名称改为 is_«model_attribute»_«state name»()。同样,自动转换将被命名为 to_«model_attribute»_«state name»() 而不是 to_«state name»()。这样做是为了允许多个机器在同一个模型上工作,每个都有独立的状态属性名称。
lump = 物质()
machine = Machine(lump, states=['固态', '液态', '气态'], model_attribute='物质状态', initial='固态')
lump.物质状态
>>> '固态'
# 使用自定义的 'model_attribute',也可以这样检查状态:
lump.is_物质状态_固态()
>>> True
lump.to_物质状态_气态()
>>> True
枚举
到目前为止,我们已经看到了如何给出状态名称并使用这些名称来处理我们的状态机。 如果你偏爱更严格的类型和更多的 IDE 代码补全(或者你就是打不出 'sesquipedalophobia' 这个词了,因为这个词吓到你了),使用枚举可能正是你想要的:
import enum # Python 2.7 用户需要安装 'enum34'
from transitions import Machine
class 状态(enum.Enum):
错误 = 0
红 = 1
黄 = 2
绿 = 3
transitions = [['前进', 状态.红, 状态.黄],
['前进', 状态.黄, 状态.绿],
['出错', '*', 状态.错误]]
m = Machine(states=状态, transitions=transitions, initial=状态.红)
assert m.is_红()
assert m.state is 状态.红
state = m.get_state(状态.红) # 获取 transitions.State 对象
print(state.name) # >>> 红
m.前进()
m.前进()
assert m.is_绿()
m.出错()
assert m.state is 状态.错误
如果你愿意,可以混合使用枚举和字符串(例如 [状态.红, '橙色', 状态.黄, 状态.绿]),但请注意,在内部,transitions 仍然会按名称(enum.Enum.name)处理状态。
因此,不能同时拥有状态 '绿' 和 状态.绿。
转换
上面的一些例子已经顺便说明了转换的用法,但在这里我们将更详细地探讨它们。
与状态一样,每个转换在内部都表示为其自身的对象——Transition 类的一个实例。初始化一组转换的最快方法是向 Machine 初始化器传递一个字典或字典列表。我们上面已经看到了:
transitions = [
{ 'trigger': '融化', 'source': '固态', 'dest': '液态' },
{ 'trigger': '蒸发', 'source': '液态', 'dest': '气态' },
{ 'trigger': '升华', 'source': '固态', 'dest': '气态' },
{ 'trigger': '电离', 'source': '气态', 'dest': '等离子态' }
]
machine = Machine(model=物质(), states=states, transitions=transitions)
用字典定义转换的好处是清晰,但可能很繁琐。如果你追求简洁,你可以选择使用列表来定义转换。只需确保每个列表中的元素顺序与 Transition 初始化中的位置参数顺序相同(即,trigger、source、destination 等)。
下面的列表的列表在功能上等同于上面的字典列表:
transitions = [
['融化', '固态', '液态'],
['蒸发', '液态', '气态'],
['升华', '固态', '气态'],
['电离', '气态', '等离子态']
]
或者,你也可以在初始化后向 Machine 添加转换:
machine = Machine(model=lump, states=states, initial='固态')
machine.add_transition('融化', source='固态', dest='液态')
触发转换
要执行一个转换,需要某个事件来触发它。有两种方法可以做到这一点:
-
使用自动附加到基本模型的方法:
>>> lump.融化() >>> lump.state '液态' >>> lump.蒸发() >>> lump.state '气态'注意,你不需要在任何地方显式定义这些方法;每个转换的名称都绑定到传递给
Machine初始化器的模型(在这个例子中是lump)。这也意味着你的模型不应该已经包含与事件触发器同名的方法,因为transitions只会在该位置未被占用时才会将便捷方法附加到你的模型上。如果你想修改这种行为,请查看 FAQ。 -
使用现在已附加到你的模型上的
trigger方法(如果之前没有的话)。这个方法让你可以按名称执行转换,以防需要动态触发:>>> lump.trigger('融化') >>> lump.state '液态' >>> lump.trigger('蒸发') >>> lump.state '气态'
触发无效转换
默认情况下,触发无效转换将引发异常:
>>> lump.to_气态()
>>> # 这行不通,因为只有处于固态的对象才能融化
>>> lump.融化()
transitions.core.MachineError: "无法从状态 '气态' 触发事件 '融化'!"
这种行为通常是可取的,因为它有助于提醒你代码中的问题。但在某些情况下,你可能希望静默忽略无效触发器。你可以通过设置 ignore_invalid_triggers=True 来实现这一点(可以在逐个状态的基础上设置,也可以全局为所有状态设置):
>>> # 全局抑制无效触发器异常
>>> m = Machine(lump, states, initial='固态', ignore_invalid_triggers=True)
>>> # ...或者只为某一组状态抑制
>>> states = ['新状态1', '新状态2']
>>> m.add_states(states, ignore_invalid_triggers=True)
>>> # ...甚至只为一个状态。在这里,只有当当前状态是 A 时才会抑制异常。
>>> states = [State('A', ignore_invalid_triggers=True), 'B', 'C']
>>> m = Machine(lump, states)
>>> # ...如果只有一个状态应该引发异常,也可以反过来
>>> # 因为机器的全局值不会应用于先前初始化的状态。
>>> states = ['A', 'B', State('C')] # 'ignore_invalid_triggers' 的默认值是 False
>>> m = Machine(lump, states, ignore_invalid_triggers=True)
如果你需要知道从某个状态哪些转换是有效的,你可以使用 get_triggers:
m.get_triggers('固态')
>>> ['融化', '升华']
m.get_triggers('液态')
>>> ['蒸发']
m.get_triggers('等离子态')
>>> []
# 你也可以一次查询多个状态
m.get_triggers('固态', '液态', '气态', '等离子态')
>>> ['融化', '蒸发', '升华', '电离']
如果你从一开始就关注此文档,你会注意到 get_triggers 实际上返回的触发器比上面显示的显式定义的触发器更多,例如 to_液态 等等。
这些被称为 自动转换,将在下一节介绍。
所有状态的自动转换
除了显式添加的任何转换外,每当一个状态被添加到 Machine 实例时,都会自动创建一个 to_«state»() 方法。这个方法会转换到目标状态,无论机器当前处于哪个状态:
lump.to_液态()
lump.state
>>> '液态'
lump.to_固态()
lump.state
>>> '固态'
如果你希望,可以通过在 Machine 初始化器中设置 auto_transitions=False 来禁用此行为。
从多个状态转换
一个给定的触发器可以附加到多个转换,其中一些可能开始或结束于相同的状态。例如:
machine.add_transition('嬗变', ['固态', '液态', '气态'], '等离子态')
machine.add_transition('嬗变', '等离子态', '固态')
# 下一个转换永远不会执行
machine.add_transition('嬗变', '等离子态', '气态')
在这种情况下,调用 嬗变() 如果模型当前处于 '等离子态',则将模型的状态设置为 '固态',否则将其设置为 '等离子态'。(注意,只有第一个匹配的转换会执行;因此,上面最后一行定义的转换不会做任何事情。)
你也可以让一个触发器从所有状态转换到特定目的地,使用 '*' 通配符:
machine.add_transition('to_液态', '*', '液态')
请注意,通配符转换只适用于在调用 add_transition() 时存在的状态。当模型处于添加转换之后才定义的状态时,调用基于通配符的转换将引发无效转换消息,并且不会转换到目标状态。
来自多个状态的自反转换
自反触发器(源状态和目标状态相同的触发器)可以很容易地通过指定 = 作为目的地来添加。
如果同一个自反触发器需要添加到多个状态,这很方便。
例如:
machine.add_transition('触摸', ['液态', '气态', '等离子态'], '=', after='改变形状')
这将为所有三个状态添加自反转换,以 触摸() 作为触发器,并在每次触发后执行 改变形状。
内部转换
与自反转换相反,内部转换实际上永远不会离开状态。
这意味着诸如 before 或 after 等与转换相关的回调将被处理,而状态相关的回调 exit 或 enter 则不会。
要将转换定义为内部转换,将目标设置为 None。
machine.add_transition('内部', ['液态', '气态'], None, after='改变形状')
有序转换
一个常见的需求是状态转换遵循严格的线性顺序。例如,给定状态 ['A', 'B', 'C'],你可能只想要 A → B、B → C 和 C → A 的有效转换(但没有其他配对)。
为了便于实现这种行为,Transitions 在 Machine 类中提供了 add_ordered_transitions() 方法:
states = ['A', 'B', 'C']
# 查看“替代初始化”部分,了解 init 第一个参数的说明
machine = Machine(states=states, initial='A')
machine.add_ordered_transitions()
machine.next_state()
print(machine.state)
>>> 'B'
# 我们也可以定义不同的转换顺序
machine = Machine(states=states, initial='A')
machine.add_ordered_transitions(['A', 'C', 'B'])
machine.next_state()
print(machine.state)
>>> 'C'
# 条件也可以传递给 'add_ordered_transitions'
# 如果传递了一个条件,它将用于所有转换
machine = Machine(states=states, initial='A')
machine.add_ordered_transitions(conditions='检查')
# 如果传递了一个列表,它必须包含与机器包含的状态数完全相同的元素
# (A->B, ..., X->A)
machine = Machine(states=states, initial='A')
machine.add_ordered_transitions(conditions=['检查_A2B', ..., '检查_X2A'])
# 条件总是从初始状态开始应用
machine = Machine(states=states, initial='B')
machine.add_ordered_transitions(conditions=['检查_B2C', ..., '检查_A2B'])
# 使用 `loop=False`,从最后一个状态到第一个状态的转换将被省略(例如 C->A)
# 当你也传递条件时,你需要少传递一个条件(len(states)-1)
machine = Machine(states=states, initial='A')
machine.add_ordered_transitions(loop=False)
machine.next_state()
machine.next_state()
machine.next_state() # transitions.core.MachineError: "无法从状态 C 触发事件 next_state!"
队列转换
Transitions 中的默认行为是即时处理事件。这意味着在 on_enter 方法内的事件将在绑定到 after 的回调被调用之前就被处理。
def 去C():
global machine
machine.to_C()
def after_advance():
print("我现在在状态 B 了!")
def entering_C():
print("我现在在状态 C 了!")
states = ['A', 'B', 'C']
machine = Machine(states=states, initial='A')
# 我们想在状态转换到 B 完成时得到一条消息
machine.add_transition('前进', 'A', 'B', after=after_advance)
# 调用从状态 B 到状态 C 的转换
machine.on_enter_B(去C)
# 我们也想在进入状态 C 时得到一条消息
machine.on_enter_C(entering_C)
machine.前进()
>>> '我现在在状态 C 了!'
>>> '我现在在状态 B 了!' # 啥?
这个例子的执行顺序是
准备 -> before -> on_enter_B -> on_enter_C -> after。
如果启用了队列处理,一个转换将在下一个转换被触发之前完成:
machine = Machine(states=states, queued=True, initial='A')
...
machine.前进()
>>> '我现在在状态 B 了!'
>>> '我现在在状态 C 了!' # 这样好多了!
这导致
准备 -> before -> on_enter_B -> queue(to_C) -> after -> on_enter_C。
重要提示: 当在队列中处理事件时,触发器调用将始终返回 True,因为在排队时无法确定涉及排队调用的转换最终是否会成功完成。即使只处理单个事件也是如此。
machine.add_transition('跳跃', 'A', 'C', conditions='将会失败')
...
# queued=False
machine.跳跃()
>>> False
# queued=True
machine.跳跃()
>>> True
当模型从机器中移除时,transitions 也会从队列中移除所有相关事件。
class Model:
def on_enter_B(self):
self.to_C() # 添加事件到队列 ...
self.machine.remove_model(self) # 然后... 没了
条件转换
有时你只想在特定条件出现时才执行某个转换。你可以通过传递一个方法或方法列表到 conditions 参数来实现:
# 我们的物质类,现在有一堆返回布尔值的方法。
class 物质(object):
def 是可燃的(self): return False
def 真的很热(self): return True
machine.add_transition('加热', '固态', '气态', conditions='是可燃的')
machine.add_transition('加热', '固态', '液态', conditions=['真的很热'])
在上面的例子中,当模型处于状态 '固态' 时调用 加热(),如果 是可燃的 返回 True,将转换到状态 '气态'。否则,如果 真的很热 返回 True,它将转换到状态 '液态'。
为方便起见,还有一个 'unless' 参数,其行为与 conditions 完全相同,但取反:
machine.add_transition('加热', '固态', '气态', unless=['是可燃的', '真的很热'])
在这种情况下,只要 加热() 触发,模型就会从固态转换到气态,前提是 是可燃的() 和 真的很热() 都返回 False。
请注意,条件检查方法将被动接收传递给触发方法的可选参数和/或数据对象。例如,以下调用:
lump.加热(temp=74)
# 等价于 lump.trigger('加热', temp=74)
... 将把 temp=74 可选关键字参数传递给 是可燃的() 检查(可能包装在 EventData 实例中)。更多关于此的内容,请参见下面的 传递数据 部分。
检查转换
如果你想在继续之前确保转换是可能的,你可以使用已添加到你的模型中的 may_<trigger_name> 函数。
你的模型还包含 may_trigger 函数来按名称检查触发器:
# 检查当前温度是否足够热以触发转换
if lump.may_加热():
# 如果 lump.may_trigger("加热"):
lump.加热()
这将执行所有 准备 回调并评估分配给潜在转换的条件。
当转换的目标不可用(尚未)时,也可以使用转换检查:
machine.add_transition('升华', '固态', '精神层面')
assert not lump.may_升华() # 还没准备好 :(
assert not lump.may_trigger("升华") # 通过触发器名称检查的结果相同
回调
你不仅可以将回调附加到状态,还可以附加到转换。每个转换都有 'before' 和 'after' 属性,其中包含在转换执行之前和之后要调用的方法列表:
class 物质(object):
def 发出嘶嘶声(self): print("嘶嘶嘶嘶嘶嘶嘶嘶嘶嘶")
def 消失(self): print("所有液体都去哪儿了?")
transitions = [
{ 'trigger': '融化', 'source': '固态', 'dest': '液态', 'before': '发出嘶嘶声'},
{ 'trigger': '蒸发', 'source': '液态', 'dest': '气态', 'after': '消失' }
]
lump = 物质()
machine = Machine(lump, states, transitions=transitions, initial='固态')
lump.融化()
>>> "嘶嘶嘶嘶嘶嘶嘶嘶嘶嘶"
lump.蒸发()
>>> "所有液体都去哪儿了?"
还有一个 'prepare' 回调,它会在转换一开始就执行,在任何 'conditions' 检查或其他回调执行之前。
class 物质(object):
heat = False
attempts = 0
def 计数尝试(self): self.attempts += 1
def 加热(self): self.heat = random.random() < 0.25
def 统计(self): print('你花了 %i 次尝试才融化这块东西!' %self.attempts)
@property
def 真的很热(self):
return self.heat
states=['固态', '液态', '气态', '等离子态']
transitions = [
{ 'trigger': '融化', 'source': '固态', 'dest': '液态', 'prepare': ['加热', '计数尝试'], 'conditions': '真的很热', 'after': '统计'},
]
lump = 物质()
machine = Machine(lump, states, transitions=transitions, initial='固态')
lump.融化()
lump.融化()
lump.融化()
lump.融化()
>>> "你花了 4 次尝试才融化这块东西!"
请注意,除非当前状态是命名转换的有效源,否则 prepare 不会被调用。
意为在每次转换之前或之后执行的默认动作可以分别通过 before_state_change 和 after_state_change 在初始化期间传递给 Machine:
class 物质(object):
def 发出嘶嘶声(self): print("嘶嘶嘶嘶嘶嘶嘶嘶嘶嘶")
def 消失(self): print("所有液体都去哪儿了?")
states=['固态', '液态', '气态', '等离子态']
lump = 物质()
m = Machine(lump, states, before_state_change='发出嘶嘶声', after_state_change='消失')
lump.to_气态()
>>> "嘶嘶嘶嘶嘶嘶嘶嘶嘶嘶"
>>> "所有液体都去哪儿了?"
还有两个关键字用于回调,这些回调应该独立于 a) 有多少转换是可能的,b) 任何转换是否成功以及 c) 即使在其他回调执行期间引发错误,也应该执行。
通过 prepare_event 传递给 Machine 的回调将在处理可能的转换(及其各自的 prepare 回调)之前执行一次。
finalize_event 的回调将无论已处理转换的成功与否都会执行。
请注意,如果发生错误,它将被附加到 event_data 作为 error,并且可以通过 send_event=True 检索。
from transitions import Machine
class 物质(object):
def 引发错误(self, event): raise ValueError("哦不")
def 准备(self, event): print("我准备好了!")
def 最终处理(self, event): print("结果:", type(event.error), event.error)
states=['固态', '液态', '气态', '等离子态']
lump = 物质()
m = Machine(lump, states, prepare_event='准备', before_state_change='引发错误',
finalize_event='最终处理', send_event=True)
try:
lump.to_气态()
except ValueError:
pass
print(lump.state)
# >>> 我准备好了!
# >>> 结果: <class 'ValueError'> 哦不
# >>> 初始状态
有时事情就是不如预期,我们需要处理异常并清理混乱以保持事情进行。
我们可以将回调传递给 on_exception 来做到这一点:
from transitions import Machine
class 物质(object):
def 引发错误(self, event): raise ValueError("哦不")
def 处理错误(self, event):
print("修复中...")
del event.error # 如果我们看不到它,那它就没发生...
states=['固态', '液态', '气态', '等离子态']
lump = 物质()
m = Machine(lump, states, before_state_change='引发错误', on_exception='处理错误', send_event=True)
try:
lump.to_气态()
except ValueError:
pass
print(lump.state)
# >>> 修复中...
# >>> 初始状态
可调用对象解析
你可能已经意识到,将可调用对象传递给状态、条件和转换的标准方式是通过名称。当处理回调和条件时,transitions 将使用它们的名称从模型中检索相关的可调用对象。如果无法检索到该方法并且它包含点,transitions 将把该名称视为模块函数的路径并尝试导入它。或者,你可以传递属性或特性的名称。它们将被包装成函数,但显然不能接收事件数据。你也可以直接传递可调用对象,例如(绑定的)函数。如前所述,你也可以将可调用对象名称的列表/元组传递给回调参数。回调将按照它们被添加的顺序执行。
from transitions import Machine
from mod import 导入的函数
import random
class 模型(object):
def 一个回调(self):
导入的函数()
@property
def 一个特性(self):
""" 基本上是抛硬币。 """
return random.random() < 0.5
一个属性 = False
model = 模型()
machine = Machine(model=model, states=['A'], initial='A')
machine.add_transition('按名称', 'A', 'A', conditions='一个特性', after='一个回调')
machine.add_transition('按引用', 'A', 'A', unless=['一个特性', '一个属性'], after=model.一个回调)
machine.add_transition('导入的', 'A', 'A', after='mod.导入的函数')
model.按名称()
model.按引用()
model.导入的()
可调用对象的解析在 Machine.resolve_callable 中完成。
如果需要更复杂的可调用对象解析策略,可以重写此方法。
示例
class 自定义机器(Machine):
@staticmethod
def resolve_callable(func, event_data):
# 在这里操作参数,并返回 func,或者如果不进行操作,则返回 super()。
super(自定义机器, 自定义机器).resolve_callable(func, event_data)
回调执行顺序
总结一下,目前有三种触发事件的方式。你可以调用模型的便捷函数,如 lump.融化(),
通过名称执行触发器,如 lump.trigger("融化"),或者使用 machine.dispatch("融化") 在多个模型上分派事件
(请参阅 替代初始化模式 中关于多个模型的部分)。
转换上的回调将按以下顺序执行:
| 回调 | 当前状态 | 说明 |
|---|---|---|
'machine.prepare_event' |
源 |
在开始处理各个转换之前执行一次 |
'transition.prepare' |
源 |
转换一开始就执行 |
'transition.conditions' |
源 |
条件可能失败并停止转换 |
'transition.unless' |
源 |
条件可能失败并停止转换 |
'machine.before_state_change' |
源 |
在模型上声明的默认回调 |
'transition.before' |
源 |
|
'state.on_exit' |
源 |
在源状态上声明的回调 |
<状态改变> |
||
'state.on_enter' |
目标 |
在目标状态上声明的回调 |
'transition.after' |
目标 |
|
'machine.on_final' |
目标 |
子级的回调将首先被调用 |
'machine.after_state_change' |
目标 |
在模型上声明的默认回调;内部转换之后也会调用 |
'machine.on_exception' |
源/目标 |
当引发异常时将执行回调 |
'machine.finalize_event' |
源/目标 |
即使没有发生转换或引发了异常,也会执行回调 |
如果任何回调引发异常,回调的处理将不会继续。这意味着当转换之前发生错误(在 state.on_exit 或更早),转换会被停止。如果在转换已经进行之后发生错误(在 state.on_enter 或更晚),状态更改会持久化,不会发生回滚。除非异常是由最终化回调本身引发的,否则在 machine.finalize_event 中指定的回调将始终执行。请注意,每个回调序列必须在下一个阶段执行之前完成。阻塞回调将停止执行顺序,从而阻塞 trigger 或 dispatch 调用本身。如果你希望回调并行执行,可以查看 扩展 中的 AsyncMachine 用于异步处理或 LockedMachine 用于线程。
传递数据
有时你需要将一些数据传递给在机器初始化时注册的回调函数,这些数据反映了模型的当前状态。 Transitions 允许你以两种不同的方式做到这一点。
首先(默认),你可以将任何位置参数或关键字参数直接传递给触发器方法(在你调用 add_transition() 时创建的方法):
class 物质(object):
def __init__(self): self.设置环境()
def 设置环境(self, temp=0, pressure=101.325):
self.temp = temp
self.pressure = pressure
def 打印温度(self): print("当前温度是 %d 摄氏度。" % self.temp)
def 打印压力(self): print("当前压力是 %.2f 千帕。" % self.pressure)
lump = 物质()
machine = Machine(lump, ['固态', '液态'], initial='固态')
machine.add_transition('融化', '固态', '液态', before='设置环境')
lump.融化(45) # 位置参数;
# 等价于 lump.trigger('融化', 45)
lump.打印温度()
>>> '当前温度是 45 摄氏度。'
machine.set_state('固态') # 重置状态以便我们能再次融化
lump.融化(pressure=300.23) # 关键字参数也有效
lump.打印压力()
>>> '当前压力是 300.23 千帕。'
你可以向触发器传递任意数量的参数。
这种方法有一个重要的限制:由状态转换触发的每个回调函数都必须能够处理所有参数。如果每个回调期望的数据有些不同,这可能会引起问题。
为了解决这个问题,Transitions 支持一种替代的发送数据方法。如果你在 Machine 初始化时设置 send_event=True,所有触发器的参数都将包装在一个 EventData 实例中并传递给每个回调。(EventData 对象还在内部维护对事件的源状态、模型、转换、机器和触发器的引用,以防你需要访问这些内容做任何事情。)
class 物质(object):
def __init__(self):
self.temp = 0
self.pressure = 101.325
# 注意,唯一的参数现在是 EventData 实例。
# 这个对象存储传递给触发器方法的位置参数在 .args 属性中,
# 存储关键字参数在 .kwargs 字典中。
def 设置环境(self, event):
self.temp = event.kwargs.get('temp', 0)
self.pressure = event.kwargs.get('pressure', 101.325)
def 打印压力(self): print("当前压力是 %.2f 千帕。" % self.pressure)
lump = 物质()
machine = Machine(lump, ['固态', '液态'], send_event=True, initial='固态')
machine.add_transition('融化', '固态', '液态', before='设置环境')
lump.融化(temp=45, pressure=1853.68) # 关键字参数
lump.打印压力()
>>> '当前压力是 1853.68 千帕。'
替代初始化模式
到目前为止的所有例子中,我们都将一个新的 Machine 实例附加到一个单独的模型(lump,物质 类的一个实例)。虽然这种分离保持了整洁(因为你不需要将一大堆新方法打补丁到 物质 类中),但它也可能变得烦人,因为它要求你跟踪哪些方法是在状态机上调用的,哪些是在状态机绑定的模型上调用的(例如,lump.on_enter_StateA() 与 machine.add_transition())。
幸运的是,Transitions 很灵活,支持另外两种初始化模式。
首先,你可以创建一个独立的状态机,完全不需要另一个模型。只需在初始化时省略模型参数:
machine = Machine(states=states, transitions=transitions, initial='固态')
machine.融化()
machine.state
>>> '液态'
如果你以这种方式初始化机器,那么你可以将所有触发事件(如 蒸发()、升华() 等)和所有回调函数直接附加到 Machine 实例。
这种方法的好处是将所有状态机功能集中在一个地方,但如果你认为状态逻辑应该包含在模型本身内,而不是在一个单独的控制器中,可能会感觉有点不自然。
另一种(可能更好的)方法是让模型继承 Machine 类。Transitions 设计为无缝支持继承。(只需确保重写类 Machine 的 __init__ 方法!):
class 物质(Machine):
def 问好(self): print("你好,新状态!")
def 道别(self): print("再见,旧状态!")
def __init__(self):
states = ['固态', '液态', '气态']
Machine.__init__(self, states=states, initial='固态')
self.add_transition('融化', '固态', '液态')
lump = 物质()
lump.state
>>> '固态'
lump.融化()
lump.state
>>> '液态'
在这里,你可以将所有状态机功能整合到你现有的模型中,这通常比把所有我们想要的功能放在一个单独的独立 Machine 实例中感觉更自然。
一台机器可以处理多个模型,这些模型可以作为列表传递,如 Machine(model=[model1, model2, ...])。
如果你想添加模型以及机器实例本身,你可以在初始化时传递类变量占位符(字符串) Machine.self_literal,如 Machine(model=[Machine.self_literal, model1, ...])。
你也可以创建一个独立的机器,并通过 machine.add_model 动态注册模型,方法是将 model=None 传递给构造函数。
此外,你可以使用 machine.dispatch 在所有当前添加的模型上触发事件。
如果机器是长期存在的,而你的模型是临时的并且应该被垃圾回收,请记住调用 machine.remove_model:
class 物质():
pass
lump1 = 物质()
lump2 = 物质()
# 将 'model' 设置为 None 或传递一个空列表将初始化一个没有模型的机器
machine = Machine(model=None, states=states, transitions=transitions, initial='固态')
machine.add_model(lump1)
machine.add_model(lump2, initial='液态')
lump1.state
>>> '固态'
lump2.state
>>> '液态'
# 自定义事件以及自动转换都可以被分派到所有模型
machine.dispatch("to_等离子态")
lump1.state
>>> '等离子态'
assert lump1.state == lump2.state
machine.remove_model([lump1, lump2])
del lump1 # lump1 被垃圾回收
del lump2 # lump2 被垃圾回收
如果你不在状态机构造函数中提供初始状态,transitions 将创建并添加一个名为 '初始' 的默认状态。
如果你不想要默认的初始状态,你可以传递 initial=None。
但是,在这种情况下,每次添加模型时都需要传递一个初始状态。
machine = Machine(model=None, states=states, transitions=transitions, initial=None)
machine.add_model(物质())
>>> "MachineError: 机器未配置初始状态,必须在添加模型时指定。"
machine.add_model(物质(), initial='液态')
具有多个状态的模型可以使用不同的 model_attribute 值附加多个机器。如 检查状态 中所述,这将添加自定义的 is/to_<model_attribute>_<state_name> 函数:
lump = 物质()
物质机器 = Machine(lump, states=['固态', '液态', '气态'], initial='固态')
# 向同一个模型添加第二个机器,但分配不同的状态属性
运输机器 = Machine(lump, states=['已交付', '运输中'], initial='已交付', model_attribute='运输状态')
lump.state
>>> '固态'
lump.is_固态() # 检查默认字段
>>> True
lump.运输状态
>>> '已交付'
lump.is_运输状态_已交付() # 检查自定义字段。
>>> True
lump.to_运输状态_运输中()
>>> True
lump.is_运输状态_已交付()
>>> False
日志记录
Transitions 包含非常基本的日志记录功能。一些事件——即状态更改、转换触发和条件检查——使用标准的 Python logging 模块作为 INFO 级别事件记录。这意味着你可以在脚本中轻松配置日志记录到标准输出:
# 设置日志记录;基本日志级别将是 DEBUG
import logging
logging.basicConfig(level=logging.DEBUG)
# 将 transitions 的日志级别设置为 INFO;将省略 DEBUG 消息
logging.getLogger('transitions').setLevel(logging.INFO)
# 照常进行
machine = Machine(states=states, transitions=transitions, initial='固态')
...
(重新)存储机器实例
机器是可 pickle 的,可以使用 pickle 存储和加载。对于 Python 3.3 及更早版本,需要 dill。
import dill as pickle # 仅适用于 Python 3.3 及更早版本
m = Machine(states=['A', 'B', 'C'], initial='A')
m.to_B()
m.state
>>> B
# 存储机器
dump = pickle.dumps(m)
# 再次加载 Machine 实例
m2 = pickle.loads(dump)
m2.state
>>> B
m2.states.keys()
>>> ['A', 'B', 'C']
类型支持
你可能已经注意到,transitions 使用了一些 Python 的动态特性,为你提供了处理模型的便捷方法。然而,静态类型检查器不喜欢在运行时之前未知的模型属性和方法。历史上,transitions 也不会分配模型上已经定义的便捷方法,以防止意外覆盖。
但别担心!你可以使用机器构造参数 model_override 来改变模型的装饰方式。如果你设置 model_override=True,transitions 将只覆盖已经定义的方法。这可以防止新方法在运行时出现,并且也允许你定义你想使用哪些辅助方法。
from transitions import Machine
# 动态分配
class 模型:
pass
model = 模型()
default_machine = Machine(model, states=["A", "B"], transitions=[["go", "A", "B"]], initial="A")
print(model.__dict__.keys()) # 所有便捷函数都已被分配
# >> dict_keys(['trigger', 'to_A', 'may_to_A', 'to_B', 'may_to_B', 'go', 'may_go', 'is_A', 'is_B', 'state'])
assert model.is_A() # 类 '模型' 的未解析属性引用 'is_A'
# 预定义分配:我们只对调用我们的 'go' 事件感兴趣,其他事件将通过名称触发
class 预定义模型:
# state(或者如果你设置了 'model_attribute' 则是另一个参数)无论如何都会被分配
# 因为我们需要跟踪模型的状态
state: str
def go(self) -> bool:
raise RuntimeError("应该被覆盖!")
def trigger(self, trigger_name: str) -> bool:
raise RuntimeError("应该被覆盖!")
model = 预定义模型()
override_machine = Machine(model, states=["A", "B"], transitions=[["go", "A", "B"]], initial="A", model_override=True)
print(model.__dict__.keys())
# >> dict_keys(['trigger', 'go', 'state'])
model.trigger("to_B")
assert model.state == "B"
如果你想使用所有便捷函数并加入一些回调,当你有很多状态和转换时,定义一个模型会变得相当复杂。
transitions 中的方法 generate_base_model 可以从机器配置生成一个基础模型来帮助你。
from transitions.experimental.utils import generate_base_model
simple_config = {
"states": ["A", "B"],
"transitions": [
["go", "A", "B"],
],
"initial": "A",
"before_state_change": "call_this",
"model_override": True,
}
class_definition = generate_base_model(simple_config)
with open("base_model.py", "w") as f:
f.write(class_definition)
# ... 在另一个文件中
from transitions import Machine
from base_model import BaseModel
class Model(BaseModel): # call_this 在 BaseModel 中将是抽象方法
def call_this(self) -> None:
# 做些事情
model = Model()
machine = Machine(model, **simple_config)
定义将被覆盖的模型方法会增加一些额外的工作。
确保事件名称拼写正确可能很麻烦,尤其是在状态和转换在你的模型之前或之后在列表中定义的情况下。你可以通过将状态定义为枚举来减少样板文件和工作字符串的不确定性。你还可以借助 add_transitions 和 event 在模型类中直接定义转换。
取决于你喜欢的代码风格,你可以使用函数装饰器 add_transitions 还是 event 来为属性赋值。
它们的工作方式相同,具有相同的签名,并且应该产生(几乎)相同的 IDE 类型提示。
由于这仍然是一项正在进行的工作,你需要创建一个自定义的 Machine 类,并使用 with_model_definitions 来让 transitions 检查以这种方式定义的转换。
from enum import Enum
from transitions.experimental.utils import with_model_definitions, event, add_transitions, transition
from transitions import Machine
class State(Enum):
A = "A"
B = "B"
C = "C"
class Model:
state: State = State.A
@add_transitions(transition(source=State.A, dest=State.B), [State.C, State.A])
@add_transitions({"source": State.B, "dest": State.A})
def foo(self): ...
bar = event(
{"source": State.B, "dest": State.A, "conditions": lambda: False},
transition(source=State.B, dest=State.C)
)
@with_model_definitions # 别忘了用这个装饰器定义你的模型!
class MyMachine(Machine):
pass
model = Model()
machine = MyMachine(model, states=State, initial=model.state)
model.foo()
model.bar()
assert model.state == State.C
model.foo()
assert model.state == State.A
扩展
尽管 transitions 的核心保持轻量级,但有各种各样的 MixIns 来扩展其功能。目前支持的有:
- 分层状态机 用于嵌套和重用
- 图表 用于可视化机器的当前状态
- 线程安全锁 用于并行执行
- 异步回调 用于异步执行
- 自定义状态 用于扩展与状态相关的行为
有两种机制来检索具有所需功能的启用状态机实例。
第一种方法是使用便捷 factory,四个参数 graph、nested、locked 或 asyncio 在需要该功能时设置为 True:
from transitions.extensions import MachineFactory
# 创建带有混合类的机器
diagram_cls = MachineFactory.get_predefined(graph=True)
nested_locked_cls = MachineFactory.get_predefined(nested=True, locked=True)
async_machine_cls = MachineFactory.get_predefined(asyncio=True)
# 从这些类创建实例
# 实例可以像简单机器一样使用
machine1 = diagram_cls(model, state, transitions)
machine2 = nested_locked_cls(model, state, transitions)
这种方法针对实验性使用,因为在这种情况下不需要知道底层类。
但是,类也可以直接从 transitions.extensions 导入。命名方案如下:
| 图表 | 嵌套 | 线程安全 | 异步 | |
|---|---|---|---|---|
| Machine | ✘ | ✘ | ✘ | ✘ |
| GraphMachine | ✓ | ✘ | ✘ | ✘ |
| HierarchicalMachine | ✘ | ✓ | ✘ | ✘ |
| LockedMachine | ✘ | ✘ | ✓ | ✘ |
| HierarchicalGraphMachine | ✓ | ✓ | ✘ | ✘ |
| LockedGraphMachine | ✓ | ✘ | ✓ | ✘ |
| LockedHierarchicalMachine | ✘ | ✓ | ✓ | ✘ |
| LockedHierarchicalGraphMachine | ✓ | ✓ | ✓ | ✘ |
| AsyncMachine | ✘ | ✘ | ✘ | ✓ |
| AsyncGraphMachine | ✓ | ✘ | ✘ | ✓ |
| HierarchicalAsyncMachine | ✘ | ✓ | ✘ | ✓ |
| HierarchicalAsyncGraphMachine | ✓ | ✓ | ✘ | ✓ |
要使用功能丰富的状态机,可以这样写:
from transitions.extensions import LockedHierarchicalGraphMachine as LHGMachine
machine = LHGMachine(model, states, transitions)
分层状态机 (HSM)
Transitions 包含一个允许嵌套状态的扩展模块。
这使我们能够创建上下文,并模拟状态与状态机中某些子任务相关的情况。
要创建嵌套状态,可以从 transitions 导入 NestedState,或者使用带有初始化参数 name 和 children 的字典。
可选地,可以使用 initial 来定义当进入嵌套状态时要转换到的子状态。
from transitions.extensions import HierarchicalMachine
states = ['站立', '行走', {'name': '咖啡因兴奋', 'children':['犹豫不决', '奔跑']}]
transitions = [
['走', '站立', '行走'],
['停', '行走', '站立'],
['喝', '*', '咖啡因兴奋'],
['走', ['咖啡因兴奋', '咖啡因兴奋_犹豫不决'], '咖啡因兴奋_奔跑'],
['放松', '咖啡因兴奋', '站立']
]
machine = HierarchicalMachine(states=states, transitions=transitions, initial='站立', ignore_invalid_triggers=True)
machine.走() # 现在正在行走
machine.停() # 停一下
machine.喝() # 咖啡时间
machine.state
>>> '咖啡因兴奋'
machine.走() # 我们得走快点
machine.state
>>> '咖啡因兴奋_奔跑'
machine.停() # 停不下来!
machine.state
>>> '咖啡因兴奋_奔跑'
machine.放松() # 离开嵌套状态
machine.state # 呼,这一趟真够呛
>>> '站立'
# machine.on_enter_咖啡因兴奋_奔跑('回调方法')
使用 initial 的配置可能如下所示:
# ...
states = ['站立', '行走', {'name': '咖啡因兴奋', 'initial': '犹豫不决', 'children': ['犹豫不决', '奔跑']}]
transitions = [
['走', '站立', '行走'],
['停', '行走', '站立'],
# 这个转换将结束于 '咖啡因兴奋_犹豫不决'...
['喝', '*', '咖啡因兴奋'],
# ... 这就是为什么我们不再需要在这里指定 '咖啡因兴奋' 了
['走', '咖啡因兴奋_犹豫不决', '咖啡因兴奋_奔跑'],
['放松', '咖啡因兴奋', '站立']
]
# ...
HierarchicalMachine 构造函数的 initial 关键字接受嵌套状态(例如 initial='咖啡因兴奋_奔跑')、一个被视为并行状态的列表(例如 initial=['A', 'B'])或另一个模型的当前状态(initial=model.state),该状态应该有效地是前面提到的一个选项。请注意,当传递字符串时,transition 将检查目标状态是否有 initial 子状态,并将其用作入口状态。这将递归进行,直到子状态没有提到初始状态。并行状态或作为列表传递的状态将“按原样”使用,不会进行进一步的初始评估。
请注意,你先前创建的状态对象必须是 NestedState 或其派生类。
简单 Machine 实例中使用的标准 State 类缺乏嵌套所需的功能。
from transitions.extensions.nesting import HierarchicalMachine, NestedState
from transitions import State
m = HierarchicalMachine(states=['A'], initial='初始')
m.add_state('B') # 好的
m.add_state({'name': 'C'}) # 也没问题
m.add_state(NestedState('D')) # 同样没问题
m.add_state(State('E')) # 不行!
使用嵌套状态时需要考虑的一些事项:状态名称与 NestedState.separator连接。
目前分隔符设置为下划线 ('_'),因此行为类似于基本机器。
这意味着状态 foo 的子状态 bar 将以 foo_bar 为人所知。bar 的子状态 baz 将被称为 foo_bar_baz,依此类推。
当进入一个子状态时,将为所有父状态调用 enter。退出子状态时也是如此。
第三,嵌套状态可以覆盖其父状态的转换行为。
如果当前状态不知道某个转换,它将委托给其父级。
这意味着,在标准配置中,HSM 中的状态名称绝不能包含下划线。
对于 transitions 来说,无法判断 machine.add_state('state_name') 是应该添加一个名为 state_name 的状态,还是向状态 state 添加一个子状态 name。
但在某些情况下,这还不够。
例如,如果状态名称由多个单词组成,并且你希望/需要使用下划线而不是 CamelCase 来分隔它们。
为了解决这个问题,你可以很容易地更改用于分隔的字符。
如果你使用 Python 3,你甚至可以使用花哨的 unicode 字符。
将分隔符设置为下划线以外的其他东西会改变一些行为(自动转换和设置回调),不过:
from transitions.extensions import HierarchicalMachine
from transitions.extensions.nesting import NestedState
NestedState.separator = '↦'
states = ['A', 'B',
{'name': 'C', 'children':['1', '2',
{'name': '3', 'children': ['a', 'b', 'c']}
]}
]
transitions = [
['重置', 'C', 'A'],
['重置', 'C↦2', 'C'] # 覆盖父级的重置
]
# 我们依赖自动转换
machine = HierarchicalMachine(states=states, transitions=transitions, initial='A')
machine.to_B() # 退出状态 A,进入状态 B
machine.to_C() # 退出 B,进入 C
machine.to_C.s3.a() # 进入 C↦a;进入 C↦3↦a;
machine.state
>>> 'C↦3↦a'
assert machine.is_C.s3.a()
machine.to('C↦2') # 不是交互式的;退出 C↦3↦a,退出 C↦3,进入 C↦2
machine.重置() # 退出 C↦2;C↦3 的重置已被覆盖
machine.state
>>> 'C'
machine.重置() # 退出 C,进入 A
machine.state
>>> 'A'
# s.on_enter('C↦3↦a', '回调方法')
自动转换被调用为 to_C.s3.a() 而不是 to_C_3_a()。如果你的子状态以数字开头,transitions 会为自动转换 FunctionWrapper 添加一个前缀 's'('3' 变成 's3'),以符合 Python 的属性命名方案。
如果不需要交互式补全,可以直接调用 to('C↦3↦a')。此外,on_enter/exit_<<state name>> 被替换为 on_enter/exit(state_name, callback)。状态检查可以类似地进行。可以使用 FunctionWrapper 变体 is_C.s3.a() 而不是 is_C_3_a()。
要检查当前状态是否是特定状态的子状态,is_state 支持关键字 allow_substates:
machine.state
>>> 'C.2.a'
machine.is_C() # 检查特定状态
>>> False
machine.is_C(allow_substates=True)
>>> True
assert machine.is_C.s2() is False
assert machine.is_C.s2(allow_substates=True) # FunctionWrapper 也支持 allow_substate
你也可以在 HSM 中使用枚举,但请记住 Enum 是按值比较的。
如果你在状态树中有一个值出现多次,那么这些状态就无法区分。
states = [States.RED, States.YELLOW, {'name': States.GREEN, 'children': ['tick', 'tock']}]
states = ['A', {'name': 'B', 'children': states, 'initial': States.GREEN}, States.GREEN]
machine = HierarchicalMachine(states=states)
machine.to_B()
machine.is_GREEN() # 返回 True,即使实际状态是 B_GREEN
HierarchicalMachine 已从头重写,以支持并行状态和更好的嵌套状态隔离。
这涉及一些基于社区反馈的调整。
要了解处理顺序和配置,请查看以下示例:
from transitions.extensions.nesting import HierarchicalMachine
import logging
states = ['A', 'B', {'name': 'C', 'parallel': [{'name': '1', 'children': ['a', 'b', 'c'], 'initial': 'a',
'transitions': [['go', 'a', 'b']]},
{'name': '2', 'children': ['x', 'y', 'z'], 'initial': 'z'}],
'transitions': [['go', '2_z', '2_x']]}]
transitions = [['reset', 'C_1_b', 'B']]
logging.basicConfig(level=logging.INFO)
machine = HierarchicalMachine(states=states, transitions=transitions, initial='A')
machine.to_C()
# INFO:transitions.extensions.nesting:退出状态 A
# INFO:transitions.extensions.nesting:进入状态 C
# INFO:transitions.extensions.nesting:进入状态 C_1
# INFO:transitions.extensions.nesting:进入状态 C_2
# INFO:transitions.extensions.nesting:进入状态 C_1_a
# INFO:transitions.extensions.nesting:进入状态 C_2_z
machine.go()
# INFO:transitions.extensions.nesting:退出状态 C_1_a
# INFO:transitions.extensions.nesting:进入状态 C_1_b
# INFO:transitions.extensions.nesting:退出状态 C_2_z
# INFO:transitions.extensions.nesting:进入状态 C_2_x
machine.reset()
# INFO:transitions.extensions.nesting:退出状态 C_1_b
# INFO:transitions.extensions.nesting:退出状态 C_2_x
# INFO:transitions.extensions.nesting:退出状态 C_1
# INFO:transitions.extensions.nesting:退出状态 C_2
# INFO:transitions.extensions.nesting:退出状态 C
# INFO:transitions.extensions.nesting:进入状态 B
当使用 parallel 而不是 children 时,transitions 将同时进入传递列表的所有状态。
进入哪个子状态由 initial 定义,它应该始终指向一个直接的子状态。
一个新特性是通过在状态定义中传递 transitions 关键字来定义局部转换。
上面定义的转换 ['go', 'a', 'b'] 只在 C_1 中有效。
虽然你可以像在 ['go', '2_z', '2_x'] 中那样引用子状态,但不能在局部定义的转换中直接引用父状态。
当父状态退出时,其子级也将退出。
除了从 Machine 中已知的转换处理顺序(转换按照它们添加的顺序被考虑)外,HierarchicalMachine 也会考虑层次结构。
在子状态中定义的转换将首先被评估(例如,C_1_a 在 C_2_z 之前离开),并且使用通配符 * 定义的转换将(目前)只添加转换到根状态(在这个例子中是 A、B、C)
从 0.8.0 开始,可以直接添加嵌套状态,并且将即时创建父状态:
m = HierarchicalMachine(states=['A'], initial='A')
m.add_state('B_1_a')
m.to_B_1()
assert m.is_B(allow_substates=True)
0.9.1 中的实验性功能:
你可以在状态或 HSM 本身上使用 on_final 回调。回调将在以下情况下触发:a) 状态本身被标记为 final 并且刚被进入,或者 b) 所有子状态都被认为是 final 并且至少一个子状态刚进入 final 状态。在情况 b) 下,如果条件 b) 对它们成立,所有父级也将被认为是 final。这在处理并行进行并且你的 HSM 或任何父状态应该在所有子状态都达到 final 状态时被通知的情况下可能很有用:
from transitions.extensions import HierarchicalMachine
from functools import partial
# 我们以状态 A 初始化这个并行 HSM:
# / X
# / / yI
# A -> B - Y - yII [最终]
# \ Z - zI
# \ zII [最终]
def final_event_raised(name):
print("{} 是最终状态!".format(name))
states = ['A', {'name': 'B', 'parallel': [{'name': 'X', 'final': True, 'on_final': partial(final_event_raised, 'X')},
{'name': 'Y', 'transitions': [['final_Y', 'yI', 'yII']],
'initial': 'yI',
'on_final': partial(final_event_raised, 'Y'),
'states':
['yI', {'name': 'yII', 'final': True}]
},
{'name': 'Z', 'transitions': [['final_Z', 'zI', 'zII']],
'initial': 'zI',
'on_final': partial(final_event_raised, 'Z'),
'states':
['zI', {'name': 'zII', 'final': True}]
},
],
"on_final": partial(final_event_raised, 'B')}]
machine = HierarchicalMachine(states=states, on_final=partial(final_event_raised, 'Machine'), initial='A')
# X 将立即发出最终事件
machine.to_B()
# >>> X 是最终状态!
print(machine.state)
# >>> ['B_X', 'B_Y_yI', 'B_Z_zI']
# Y 的子状态现在是最終的,將觸發 Y 的 'on_final'
machine.final_Y()
# >>> Y 是最终状态!
print(machine.state)
# >>> ['B_X', 'B_Y_yII', 'B_Z_zI']
# Z 的子状态变成最终状态,这也使得 B 的所有子级都是最终的,因此机器本身也是最终的
machine.final_Z()
# >>> Z 是最终状态!
# >>> B 是最终状态!
# >>> Machine 是最终状态!
重用先前创建的 HSM
除了语义顺序,嵌套状态在你想要为特定任务指定状态机并计划重用它们时非常方便。
在 0.8.0 之前,HierarchicalMachine 不会集成机器实例本身,而是通过创建它们的副本来集成状态和转换。
然而,从 0.8.0 开始,(Nested)State 实例只是被引用,这意味着一个机器的状态和事件集合中的更改将影响另一个机器实例。不过,模型及其状态不会被共享。
请注意,事件和转换也是通过引用复制的,如果不使用 remap 关键字,它们将被两个实例共享。
进行此更改是为了更符合 Machine,它也通过引用使用传递的 State 实例。
count_states = ['1', '2', '3', '完成']
count_trans = [
['增加', '1', '2'],
['增加', '2', '3'],
['减少', '3', '2'],
['减少', '2', '1'],
['完成', '3', '完成'],
['重置', '*', '1']
]
counter = HierarchicalMachine(states=count_states, transitions=count_trans, initial='1')
counter.增加() # 喜欢我的计数器
states = ['等待中', '收集中', {'name': '计数中', 'children': counter}]
transitions = [
['收集', '*', '收集中'],
['等待', '*', '等待中'],
['计数', '收集中', '计数中']
]
collector = HierarchicalMachine(states=states, transitions=transitions, initial='等待中')
collector.收集() # 收集中
collector.计数() # 看看我们得到了什么;计数中_1
collector.增加() # 计数中_2
collector.增加() # 计数中_3
collector.完成() # collector.state == 计数中_完成
collector.等待() # collector.state == 等待中
如果通过 children 关键字传递一个 HierarchicalMachine,该机器的初始状态将被分配给新的父状态。
在上面的例子中,我们看到进入 计数中 也会进入 计数中_1。
如果这是不希望的行为,并且机器应该停止在父状态,用户可以通过传递 initial 为 False 来实现,如 {'name': '计数中', 'children': counter, 'initial': False}。
有时你希望这样的嵌入式状态集合“返回”,这意味着在它完成后,它应该退出并转换到你的超级状态之一。
为了实现这种行为,你可以重新映射状态转换。
在上面的例子中,我们希望计数器在达到状态 完成 时返回。
这样做如下:
states = ['等待中', '收集中', {'name': '计数中', 'children': counter, 'remap': {'完成': '等待中'}}]
... # 与上面相同
collector.增加() # 计数中_3
collector.完成()
collector.state
>>> '等待中' # 注意 '计数中_完成' 将从状态机中移除
如上所述,使用 remap 将复制事件和转换,因为它们在原始状态机中可能无效。
如果一个被重用的状态机没有最终状态,你当然可以手动添加转换。
如果 'counter' 没有 '完成' 状态,我们可以添加 ['完成', 'counter_3', '等待中'] 来实现相同的行为。
如果你希望状态和转换按值而不是按引用复制(例如,如果你想保持 0.8 之前的行为),你可以通过创建一个 NestedState 并将机器的状态和事件的深拷贝分配给它来实现。
from transitions.extensions.nesting import NestedState
from copy import deepcopy
# ... 配置和创建 counter
counting_state = NestedState(name="计数中", initial='1')
counting_state.states = deepcopy(counter.states)
counting_state.events = deepcopy(counter.events)
states = ['等待中', '收集中', counting_state]
对于复杂的状态机,共享配置而不是实例化的机器可能更可行。
特别是因为实例化的机器必须派生自 HierarchicalMachine。
这样的配置可以通过 JSON 或 YAML 轻松存储和加载(请参阅 FAQ)。
HierarchicalMachine 允许使用关键字 children 或 states 定义子状态。
如果两者都存在,只考虑 children。
counter_conf = {
'name': '计数中',
'states': ['1', '2', '3', '完成'],
'transitions': [
['增加', '1', '2'],
['增加', '2', '3'],
['减少', '3', '2'],
['减少', '2', '1'],
['完成', '3', '完成'],
['重置', '*', '1']
],
'initial': '1'
}
collector_conf = {
'name': '收集器',
'states': ['等待中', '收集中', counter_conf],
'transitions': [
['收集', '*', '收集中'],
['等待', '*', '等待中'],
['计数', '收集中', '计数中']
],
'initial': '等待中'
}
collector = HierarchicalMachine(**collector_conf)
collector.收集()
collector.计数()
collector.增加()
assert collector.is_计数中_2()
图表
附加关键字:
-
title(可选):设置生成图像的标题。 -
show_conditions(默认 False):在转换边上显示条件 -
show_auto_transitions(默认 False):在图中显示自动转换 -
show_state_attributes(默认 False):在图中显示回调(进入、退出)、标签和超时
Transitions 可以生成基本的状态图,显示所有状态之间的有效转换。 基本的图表支持生成 mermaid 状态机定义,可与 mermaid 的 在线编辑器、GitLab 或 GitHub 中的 markdown 文件以及其他网络服务一起使用。 例如,此代码:
from transitions.extensions.diagrams import HierarchicalGraphMachine
import pyperclip
states = ['A', 'B', {'name': 'C',
'final': True,
'parallel': [{'name': '1', 'children': ['a', {"name": "b", "final": True}],
'initial': 'a',
'transitions': [['go', 'a', 'b']]},
{'name': '2', 'children': ['a', {"name": "b", "final": True}],
'initial': 'a',
'transitions': [['go', 'a', 'b']]}]}]
transitions = [['reset', 'C', 'A'], ["init", "A", "B"], ["do", "B", "C"]]
m = HierarchicalGraphMachine(states=states, transitions=transitions, initial="A", show_conditions=True,
title="Mermaid", graph_engine="mermaid", auto_transitions=False)
m.init()
pyperclip.copy(m.get_graph().draw(None)) # 为了方便使用 pyperclip
print("图表已复制到剪贴板!")
生成此图表(检查文档源以查看 markdown 符号):
---
Mermaid Graph
---
stateDiagram-v2
direction LR
classDef s_default fill:white,color:black
classDef s_inactive fill:white,color:black
classDef s_parallel color:black,fill:white
classDef s_active color:red,fill:darksalmon
classDef s_previous color:blue,fill:azure
state "A" as A
Class A s_previous
state "B" as B
Class B s_active
state "C" as C
C --> [*]
Class C s_default
state C {
state "1" as C_1
state C_1 {
[*] --> C_1_a
state "a" as C_1_a
state "b" as C_1_b
C_1_b --> [*]
}
--
state "2" as C_2
state C_2 {
[*] --> C_2_a
state "a" as C_2_a
state "b" as C_2_b
C_2_b --> [*]
}
}
C --> A: reset
A --> B: init
B --> C: do
C_1_a --> C_1_b: go
C_2_a --> C_2_b: go
[*] --> A
要使用更复杂的绘图功能,你需要安装 graphviz 和/或 pygraphviz。
要使用 graphviz 包生成图形,你需要手动或通过包管理器安装 Graphviz。
sudo apt-get install graphviz graphviz-dev # Ubuntu 和 Debian
brew install graphviz # MacOS
conda install graphviz python-graphviz # (Ana)conda
现在你可以安装实际的 Python 包
pip install graphviz pygraphviz # 手动安装 graphviz 和/或 pygraphviz...
pip install transitions[diagrams] # ... 或者安装带有 'diagrams' 附加功能的 transitions,它目前依赖于 pygraphviz
目前,GraphMachine 在可用时会使用 pygraphviz,并在找不到 pygraphviz 时回退到 graphviz。
如果 graphviz 也不可用,则将使用 mermaid。
可以通过向构造函数传递 graph_engine="graphviz"(或 "mermaid")来覆盖此设置。
请注意,此默认值将来可能会更改,并且可能放弃对 pygraphviz 的支持。
使用 Model.get_graph() 可以获取当前图形或感兴趣的区域 (roi) 并像这样绘制它:
# import transitions
from transitions.extensions import GraphMachine
m = Model()
# 没有进一步参数时,将使用 pygraphviz
machine = GraphMachine(model=m, ...)
# 当你想要显式使用 graphviz 时
machine = GraphMachine(model=m, graph_engine="graphviz", ...)
# 在应该显示自动转换的情况下
machine = GraphMachine(model=m, show_auto_transitions=True, ...)
# 绘制整个图形 ...
m.get_graph().draw('my_state_diagram.png', prog='dot')
# ... 或者只绘制感兴趣的区域
# (先前状态、活动状态和所有可达状态)
roi = m.get_graph(show_roi=True).draw('my_state_diagram.png', prog='dot')
这会产生类似这样的东西:
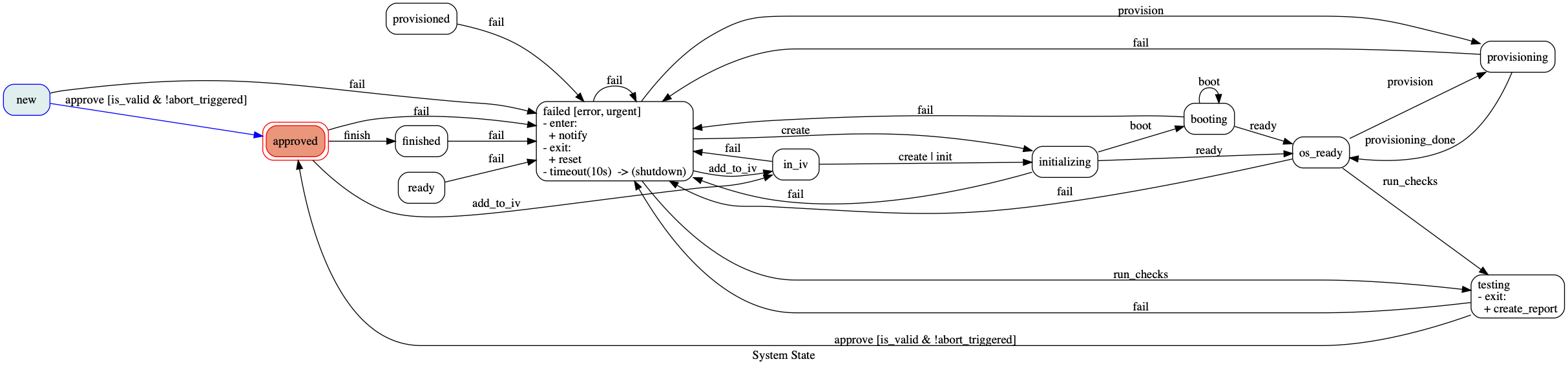
无论你使用哪个后端,draw 函数也接受文件描述符或二进制流作为第一个参数。如果你将此参数设置为 None,将返回字节流:
import io
with open('a_graph.png', 'bw') as f:
# 当你传递对象而不是文件名时,需要传递格式。
m.get_graph().draw(f, format="png", prog='dot')
# 你也可以传递一个(二进制)流
b = io.BytesIO()
m.get_graph().draw(b, format="png", prog='dot')
# 或者干脆自己处理二进制字符串
result = m.get_graph().draw(None, format="png", prog='dot')
assert result == b.getvalue()
作为回调传递的引用和部分函数将尽可能解析:
from transitions.extensions import GraphMachine
from functools import partial
class Model:
def clear_state(self, deep=False, force=False):
print("Clearing state ...")
return True
model = Model()
machine = GraphMachine(model=model, states=['A', 'B', 'C'],
transitions=[
{'trigger': 'clear', 'source': 'B', 'dest': 'A', 'conditions': model.clear_state},
{'trigger': 'clear', 'source': 'C', 'dest': 'A',
'conditions': partial(model.clear_state, False, force=True)},
],
initial='A', show_conditions=True)
model.get_graph().draw('my_state_diagram.png', prog='dot')
这应该产生类似这样的东西:

如果引用的格式不符合你的需求,你可以覆盖静态方法 GraphMachine.format_references。如果你想完全跳过引用,只需让 GraphMachine.format_references 返回 None。
另外,看看我们的 示例 IPython/Jupyter notebook,了解关于如何使用和编辑图形的更详细示例。
线程安全(-ish)状态机
在事件分派在线程中完成的情况下,可以使用 LockedMachine 或 LockedHierarchicalMachine,其中函数访问(!sic)使用可重入锁保护。
这并不能防止你通过篡改模型或状态机的成员变量来破坏你的机器。
from transitions.extensions import LockedMachine
from threading import Thread
import time
states = ['A', 'B', 'C']
machine = LockedMachine(states=states, initial='A')
# 让我们假设进入 B 需要一些时间
thread = Thread(target=machine.to_B)
thread.start()
time.sleep(0.01) # 线程需要一些时间来启动
machine.to_C() # 同步访问;在线程完成之前不会执行
# 直接访问属性
thread = Thread(target=machine.to_B)
thread.start()
machine.new_attrib = 42 # 不同步!会打乱执行顺序
任何 Python 上下文管理器都可以通过 machine_context 关键字参数传入:
from transitions.extensions import LockedMachine
from threading import RLock
states = ['A', 'B', 'C']
lock1 = RLock()
lock2 = RLock()
machine = LockedMachine(states=states, initial='A', machine_context=[lock1, lock2])
任何通过 machine_model 的上下文将在所有向 Machine 注册的模型之间共享。
也可以添加每个模型的上下文:
lock3 = RLock()
machine.add_model(model, model_context=lock3)
重要的是所有用户提供的上下文管理器都必须是可重入的,因为状态机将多次调用它们,即使在单个触发器调用的上下文中也是如此。
使用异步回调
如果你使用的是 Python 3.7 或更高版本,你可以使用 AsyncMachine 来处理异步回调。
如果你愿意,可以混合使用同步和异步回调,但这可能会有不良的副作用。
请注意,事件需要被 await,并且事件循环也必须由你处理。
from transitions.extensions.asyncio import AsyncMachine
import asyncio
import time
class AsyncModel:
def prepare_model(self):
print("我是同步的。")
self.start_time = time.time()
async def before_change(self):
print("我是异步的,现在将阻塞 100 毫秒。")
await asyncio.sleep(0.1)
print("我等完了。")
def sync_before_change(self):
print("我是同步的,将阻塞事件循环(我可能不应该这样做)")
time.sleep(0.1)
print("我同步地等完了。")
def after_change(self):
print(f"我又变成同步的了。执行花了 {int((time.time() - self.start_time) * 1000)} 毫秒。")
transition = dict(trigger="start", source="Start", dest="Done", prepare="prepare_model",
before=["before_change"] * 5 + ["sync_before_change"],
after="after_change") # 异步执行 before 函数 5 次
model = AsyncModel()
machine = AsyncMachine(model, states=["Start", "Done"], transitions=[transition], initial='Start')
asyncio.get_event_loop().run_until_complete(model.start())
# >>> 我是同步的。
# 我是异步的,现在将阻塞 100 毫秒。
# 我是异步的,现在将阻塞 100 毫秒。
# 我是异步的,现在将阻塞 100 毫秒。
# 我是异步的,现在将阻塞 100 毫秒。
# 我是异步的,现在将阻塞 100 毫秒。
# 我是同步的,将阻塞事件循环(我可能不应该这样做)
# 我同步地等完了。
# 我等完了。
# 我等完了。
# 我等完了。
# 我等完了。
# 我等完了。
# 我又变成同步的了。执行花了 101 毫秒。
assert model.is_Done()
那么,为什么你需要使用 Python 3.7 或更高版本呢?你可能会问。
异步支持早已引入。
AsyncMachine 利用 contextvars 来处理在新的转换完成之前到达的新事件:
async def await_never_return():
await asyncio.sleep(100)
raise ValueError("那花了太长时间!")
async def fix():
await m2.fix()
m1 = AsyncMachine(states=['A', 'B', 'C'], initial='A', name="m1")
m2 = AsyncMachine(states=['A', 'B', 'C'], initial='A', name="m2")
m2.add_transition(trigger='go', source='A', dest='B', before=await_never_return)
m2.add_transition(trigger='fix', source='A', dest='C')
m1.add_transition(trigger='go', source='A', dest='B', after='go')
m1.add_transition(trigger='go', source='B', dest='C', after=fix)
asyncio.get_event_loop().run_until_complete(asyncio.gather(m2.go(), m1.go()))
assert m1.state == m2.state
这个例子实际上说明了两件事:
首先,在 m1 从 A 到 B 的转换中调用的 'go' 没有被取消,其次,调用 m2.fix() 将通过执行从 A 到 C 的 'fix' 来停止 m2 从 A 到 B 的转换尝试。
没有 contextvars,这种分离是不可能的。
请注意,prepare 和 conditions 不被视为正在进行的转换。
这意味着在 conditions 被评估之后,即使另一个事件已经发生,转换也会被执行。
只有作为 before 回调或之后运行时,任务才会被取消。
AsyncMachine 具有一个模型特定的队列模式,当 queued='model' 传递给构造函数时可以使用。
使用模型特定的队列,事件只有在属于同一个模型时才会被排队。
此外,引发的异常只会清除引发该异常的模型的事件队列。
为简单起见,让我们假设下面 asyncio.gather 中的每个事件不是同时触发,而是稍微延迟的:
asyncio.gather(model1.event1(), model1.event2(), model2.event1())
# 使用 AsyncMachine(queued=True) 的执行顺序
# model1.event1 -> model1.event2 -> model2.event1
# 使用 AsyncMachine(queued='model') 的执行顺序
# (model1.event1, model2.event1) -> model1.event2
asyncio.gather(model1.event1(), model1.error(), model1.event3(), model2.event1(), model2.event2(), model2.event3())
# 使用 AsyncMachine(queued=True) 的执行顺序
# model1.event1 -> model1.error
# 使用 AsyncMachine(queued='model') 的执行顺序
# (model1.event1, model2.event1) -> (model1.error, model2.event2) -> model2.event3
请注意,队列模式在机器构造后不得更改。
向状态添加特性
如果你的超级英雄需要一些自定义行为,你可以通过装饰机器状态来添加一些额外的功能:
from time import sleep
from transitions import Machine
from transitions.extensions.states import add_state_features, Tags, Timeout
@add_state_features(Tags, Timeout)
class CustomStateMachine(Machine):
pass
class 社交超级英雄(object):
def __init__(self):
self.随从 = 0
def on_enter_等待中(self):
self.随从 += 1
states = [{'name': '准备中', 'tags': ['在家', '忙碌']},
{'name': '等待中', 'timeout': 1, 'on_timeout': '出发'},
{'name': '离开'}] # 城市需要我们!
transitions = [['完成', '准备中', '等待中'],
['加入', '等待中', '等待中'], # 再次进入等待中会增加我们的随从
['出发', '等待中', '离开']] # 好的,我们走吧
hero = 社交超级英雄()
machine = CustomStateMachine(model=hero, states=states, transitions=transitions, initial='准备中')
assert hero.state == '准备中' # 为夜班做准备
assert machine.get_state(hero.state).is_忙碌 # 我们在家并且忙碌
hero.完成()
assert hero.state == '等待中' # 等待其他超级英雄加入我们
assert hero.随从 == 1 # 目前只有我们
sleep(0.7) # 等待...
hero.加入() # 耶,我们有伴了
sleep(0.5) # 等待...
hero.加入() # 更多伙伴 \o/
sleep(2) # 等待...
assert hero.state == '离开' # 不耐烦的超级英雄已经离开了大楼
assert machine.get_state(hero.state).is_在家 is False # 是的,不再在家了
assert hero.随从 == 3 # 至少他不是一个人
目前,transitions 配备了以下状态特性:
-
超时 -- 在一段时间后触发一个事件
- 关键字:
timeout(int,可选) -- 如果传递,进入的状态将在timeout秒后超时 - 关键字:
on_timeout(字符串/可调用对象,可选) -- 当达到超时时间时将被调用 - 当设置了
timeout但未设置on_timeout时将引发AttributeError - 注意:超时在线程中触发。这意味着有几个限制(例如捕获超时中引发的异常)。对于更复杂的应用程序,请考虑事件队列。
- 关键字:
-
标签 -- 向状态添加标签
- 关键字:
tags(列表,可选) -- 为状态分配标签 - 当状态被标记为
tag_name时,State.is_<tag_name>将返回True,否则返回False
- 关键字:
-
错误 -- 当状态无法离开时引发
MachineError- 继承自
Tags(如果使用Error则不要使用Tags) - 关键字:
accepted(bool,可选) -- 将状态标记为 accepted - 或者可以传递关键字
tags,包含 'accepted' - 注意:只有当
auto_transitions设置为False时才会引发错误。否则每个状态都可以通过to_<state>方法退出。
- 继承自
-
易失性 -- 每次进入状态时初始化一个对象
- 关键字:
volatile(类,可选) -- 每次进入状态时,将分配一个类类型的对象给模型。属性名称由hook定义。如果省略,将创建一个空的 VolatileObject。 - 关键字:
hook(字符串,默认='scope') -- 临时对象的模型属性名称。
- 关键字:
你可以编写自己的 State 扩展,并以相同的方式添加它们。只需注意 add_state_features 期望混合类。这意味着你的扩展应始终调用被重写的方法 __init__、enter 和 exit。你的扩展可以继承自State,但没有它也能工作。
使用 @add_state_features 有一个缺点,那就是被装饰的机器不能被 pickle(更准确地说,动态生成的 CustomState 不能被 pickle)。
这可能是编写专用自定义状态类的原因。
根据所选的状态机,你的自定义状态类可能需要提供某些状态特性。例如,HierarchicalMachine 要求你的自定义状态是 NestedState 的实例(仅 State 是不够的)。要注入你的状态,你可以将它们分配给你的 Machine 的类属性 state_cls,或者覆盖 Machine.create_state,以防在创建状态时需要一些特定的过程:
from transitions import Machine, State
class 我的状态(State):
pass
class 自定义机器(Machine):
# 使用 我的状态 作为状态类
state_cls = 我的状态
class 详细机器(Machine):
# `Machine._create_state` 是一个类方法,但我们可以
# 覆盖它成为一个实例方法
def _create_state(self, *args, **kwargs):
print("用机器 '{0}' 创建新状态".format(self.name))
return 我的状态(*args, **kwargs)
如果你想在你的 AsyncMachine 中完全避免线程,你可以用 asyncio 扩展中的 AsyncTimeout 替换 Timeout 状态特性:
import asyncio
from transitions.extensions.states import add_state_features
from transitions.extensions.asyncio import AsyncTimeout, AsyncMachine
@add_state_features(AsyncTimeout)
class 超时机器(AsyncMachine):
pass
states = ['A', {'name': 'B', 'timeout': 0.2, 'on_timeout': 'to_C'}, 'C']
m = 超时机器(states=states, initial='A', queued=True) # 参见下面的说明
asyncio.run(asyncio.wait([m.to_B(), asyncio.sleep(0.1)]))
assert m.is_B() # 超时不应该触发
asyncio.run(asyncio.wait([m.to_B(), asyncio.sleep(0.3)]))
assert m.is_C() # 现在超时应该已经被处理了
你应该考虑将 queued=True 传递给 超时机器 构造函数。这将确保事件被顺序处理,并避免在超时和事件在接近时间发生时可能出现的异步竞争条件。
将 transitions 与 Django 一起使用
你可以看看 FAQ 来获取一些灵感,或者查看 django-transitions。
它是由 Christian Ledermann 开发的,也托管在 Github 上。
文档 包含一些用法示例。
评论已关闭